
[版权申明] 非商业目的注明出处可自由转载 出自:shusheng007
本文基于SpringAI 1.0.0-RC1版本
概述
在上一篇SpringAI开发指南(一):AI技术演进与SpringAI入门中我们介绍了一些AI应用方面的基本知识,这一篇我们主要尝试如何使用ApringAI来开发一个机器人聊天程序。
就像上一篇提到的,LLM提供商(OpenAI,DeepSeek,Google...)的大语言AI服务多是以API的形式提供的 ,所以我们要使用他们的LLM服务给我们的服务赋能时一点都不神秘:调用第三方服务的API。
这篇博客我们就展示一下如何使用SpringAI来开发一个ChatRobot.
SpringAI初体验
如果你是一个SpringBoot熟手,也许你已经想到了那老几样,没错正如你所想...
引入相关依赖
SpringAI 目前的最新版本已经到了 1.0.0-RC1 ,且此版本已经被推送到Maven中央仓库了。
为了减少版本相关的问题,使用BOM的方式引入依赖。相信使用过 SpringCloud的同学对此不会陌生,以这种方式引入依赖可以确保其包含的一系列依赖都是互相匹配的。
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>1.0.0-RC1</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
然后添加开发需要的依赖,此处我们以OpenAI的模型为例。之所以以其为例是因为OpenAI目前还是行业引领者,很多其他大模型厂商的API都是兼容OpenAI标准的,例如DeepSeek。
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-openai</artifactId>
</dependency>
上面的依赖之所以没有指定版本号是因为版本号已经在前面的BOM里指定过了。
配置
众所周知,当引入了starter后springboot会引入一系列依赖,而且会自动帮我们配置很多Bean,使我们开箱即用。然后其一般都会为我们留出很多可配置的项,我们可以在 application.yml 文件中进行自定义配置。
spring:
ai:
openai:
api-key: ${GPT_API_KEY}
chat:
options:
model: gpt-4o-mini
base-url: https://api.chatanywhere.tech
上面的配置其实已经有点冗余了,正常情况下如果你使用的是OpenAI的API,那么只需要配置一个api-key 即可,其他的都会使用默认值。
- api-key : 在OpenAPI后台申请的调用API的key
- model: 指定要使用的大模型名称。例如OpenAI有非常多的模型,这里如果不做配置的话SpringAI会默认使用 gpt-4o,但是这个随着OpenAI的升级肯定会变,所以这块最好显式设置一下
- base-url: 大模型提供提供商API的base url,我这里设置的是一个代理的地址,因为我要使用他们提供的免费OpenAI调用服务,他们会帮我跳转到OpenAI的服务去的。详情见: 如何获取免费的OpenAI与DeepSeek的API KEY
使用
前面我们一直在强调,使用LLM AI服务的过程就是调用API的过程,SpringAI帮我们抽象封装了一些工具,其中
最基本的就ChatClient,我们使用ChatClient就可以调用AI服务了。
第一步:构建ChatClient
顾名思义ChatClient是SpringAI与LLM交互的客户端,可以通过 ChatClient.Builder 来构建 。当我们引入 spring-ai-starter-model-openai 时,springboot会帮我们自动注入一个 ChatClient.Builder
感兴趣的可以查看下面代码
@Bean
@Scope("prototype")
@ConditionalOnMissingBean
ChatClient.Builder chatClientBuilder(ChatClientBuilderConfigurer chatClientBuilderConfigurer, ChatModel chatModel,
ObjectProvider<ObservationRegistry> observationRegistry,
ObjectProvider<ChatClientObservationConvention> observationConvention) {
ChatClient.Builder builder = ChatClient.builder(chatModel,
observationRegistry.getIfUnique(() -> ObservationRegistry.NOOP),
observationConvention.getIfUnique(() -> null));
return chatClientBuilderConfigurer.configure(builder);
}
在我们自己的configuration文件中实例化ChatClient
@Configuration
public class AiConfiguration {
@Bean
public ChatClient chatClient(ChatClient.Builder chatClientBuilder){
return chatClientBuilder
.defaultSystem("You are a helpful assistant")
.defaultAdvisors(new SimpleLoggerAdvisor())
.build();
}
}
我们给 ChatClient.Builder 设置了两个内容。defaultSystem是告诉LLM的角色,这里是告诉LLM要以一个有用的智能助手的角色来回答问题。defaultAdvisors后面再讲,现在只要知道这块是为了打印log的即可。
第二步:问答
现在可以在服务中注入ChatClient,然后调用LLM服务了。
@RequiredArgsConstructor
@Service
public class AssistantAppService {
private final ChatClient chatClient;
public MyChatResponse chat(MyChatRequest myChatRequest) {
...
String response = chatClient
.prompt()
.user(myChatRequest.getQuestion())
.call()
.content();
return new MyChatResponse(chatId,"", response);
}
}
如上所示,我们使用ChatClient的Fluent API来与LLM聊天。
prompt() 可以看做是你与AI交互时的模版,其负责构建与AI交互的一些必要的设置,反正就记住了必须先调用它,它有3个重载。
user() 是我们输入的提问内容。
call() 表示使用非Stream的方式去AI交互,这种方式下AI将一次性将结果返回给你,而不像我们平时与ChatGpt的APP交互那样结果是连续不断的输出的。
content() 表示返回的是字符串。
让我们尝试一下:
我写了个Controller,使用 httpie 来测试一下。
http POST localhost:8080/ai/chat chatId=王二狗 question=中国程序员有前途吗?
输出结果:
{
"answer": "中国程序员的前途总体上是非常光明的。以下是几个支持这一观点的理由:\n\n1. **行业需求**:随着科技的迅速发展和数字化转型的加速,尤其是在人工智能、大数据、云计算和区块链等领域,程序员的需求持续增长。\n\n2. **创业机会**:中国的创业环境日益成熟,许多程序员选择创业,尤其是在互联网和科技领域,能够利用自己的技术背景创造新的产品和服务。\n\n3. **国际化**:越来越多的中国公司走向国际市场,程序员的技术和经验能够在全球范围内得到认可和应用。\n\n4. **职业发展**:程序员可以通过不断学习和提升自身技能,晋升为高级工程师、架构师或管理岗位,职业发展空间广阔。\n\n5. **薪资水平**:随着技术的不断进步和行业的需求增加,程序员的薪资水平普遍较高,特别是在一线城市和热门领域。\n\n当然,程序员也面临着一些挑战,如技术更新迅速、竞争激烈等,但只要保持学习和适应能力,前途依然可期。总的来说,选择程序员职业在中国是一个值得投资的方向。",
"chainOfThought": "",
"chatId": "王二狗"
}
其实 prompt()还有其他重载,让我们看一个最复杂的
ChatClientRequestSpec prompt(Prompt prompt);
其需要一个Prompt类型的参数,其中那个Prompt又有好多重载的构造方法,我们还是看一个最复杂的
public Prompt(List<Message> messages, ChatOptions chatOptions) {
this.messages = messages;
this.chatOptions = chatOptions;
}
- messages
传给LLM的消息,其是个List,所以可以输入多条消息,可以是SystermMessage,也可以是UserMessage...
- chatOptions
每个LLM都可以设置一些调节参数,例如 temperature, topK ... ,这些都需要在实际使用过程中去调节
下面是一个例子
Message userMsg = new UserMessage(myChatRequest.getQuestion());
Prompt prompt = new Prompt(List.of(userMsg), ChatOptions.builder().temperature(0.5D).build());
String response = chatClient
.prompt(prompt)
.call()
.content();
恭喜你,你已经为你的服务进行了AI赋能!what?就这?我游戏都推了你就给我看这?
Chat Memory
不得不说,到目前为止确实没有太多的惊喜,甚至都不能完成一次有意义的对话。
以下是我与LLM的互动,
第一轮:
http POST localhost:8080/ai/chat chatId=王二狗 question=让我们来谈谈王二狗:男,爱好女,家住 天津,夫妻和睦,育有一子。
{
"answer": "王二狗是一个典型的家庭男人,生活在天津,过着平凡而幸福的生活。他的爱好是与女性交往,可能是指他喜欢与女性朋友保持良好的关系,享受社交生活。他和妻子之间的关系和睦,说明他们的婚姻生活中充满了理解与支持。他们育有一子,家庭的责任感和温暖让他的人生更加充实。\n\n如果你想更深入地讨论王二狗的生活、兴趣或其他方面,欢迎继续交流!",
"chainOfThought": "",
"chatId": "王二狗"
}
第二轮:
http POST localhost:8080/ai/chat chatId=王二狗 question=王二狗住在哪里?
{
"answer": "王二狗是一个常见的中文名字,可能指代许多不同的人。如果你有特定的王二狗的背景或者故事,请提供更多信息,这样我才能更好地帮助你。",
"chainOfThought": "",
"chatId": "王二狗"
}
你会发现LLM已经忘了我一轮告诉她的关于王二狗的信息了。这是因为LLM是无状态的,这种问题相信有点后端开发经验的人都解决过无数次了,因为通过Http调用后台服务时也是无状态的。解决办法有两个,要不将状态存储在后台,例如数据库中。要不前端请求时候带上状态,例如我们使用的cookie。
我们经常听到某某大模型可以处理多少多少token,说的就是这个事。例如一个大模型可以处理10万token,那么我们可以在每一轮和她聊天的时候就可以将前几轮的聊天历史一起交给她,那她就有了上下文... 我们称其为ChatMemory。
ChatMemory实现原理
SpringAI对应ChatMemory的支持分为3个重要部分
- BaseChatMemoryAdvisor
- ChatMemory
- ChatMemoryRepository
最终起作用的是BaseChatMemoryAdvisor,但是构建BaseChatMemoryAdvisor需要ChatMemory,而构建ChatMemory又需要ChatMemoryRepository。
BaseChatMemoryAdvisor
顾名思义,是一个Advisor,SpringAI几乎所有的功能都是通过Advisor完成的,将其理解为过滤器,或者拦截器即可。其负责在请求前读取memory交给LLM,在请求后将memory存储起来。SpringAI默认给了3个实现类,如下图所示
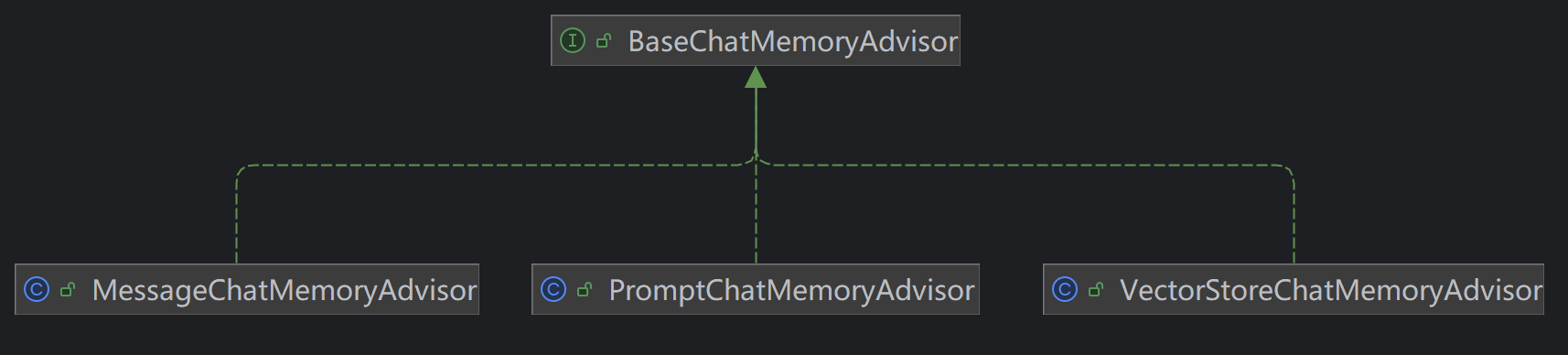
他们直接的区别只表现在如何获取memory以及以何种方式将其交给LLM。
MessageChatMemoryAdvisor
其从ChatMemory中获取memory,然后将其以message collection的形式包含在prompt,是user message。
PromptChatMemoryAdvisor
其从ChatMemory中获取memory,然后将其以plain text的形式添加到system message中。
VectorStoreChatMemoryAdvisor
其从 VectorStore中获取memory,注意已经不是从ChatMemory中获取了,然后将其以plain text的形式添加到system message中。
要使用这个advisor,需要单独引入依赖
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-advisors-vector-store</artifactId>
</dependency>
ChatMemory
ChatMemory表示对话的历史记忆,通过它可以实现添加消息,获取消息以及删除消息的功能。其定义也很简单:
public interface ChatMemory {
void add(String conversationId, List<Message> messages);
List<Message> get(String conversationId);
void clear(String conversationId);
}
可见,只有3个方法,分别对应着对一个对话历史的添加,获取和删除功能,其中 conversationId是每一个对话的标识(id)。目前SpringAI提供了1个实现类 MessageWindowChatMemory,但是其将存放具体Memory的职责又抽象了一层,由ChatMemoryRepository来承担。
private final ChatMemoryRepository chatMemoryRepository;
@Bean
public ChatMemory chatMemory() {
return MessageWindowChatMemory.builder()
.chatMemoryRepository(chatMemoryRepository)
.maxMessages(10)
.build();
}
ChatMemoryRepository
负责memory具体存储的抽象,SpringAI实现了好几个,但是除了 InMemoryChatMemoryRepository都需要单独引入依赖
- InMemoryChatMemoryRepository
- JdbcChatMemoryRepository
- CassandraChatMemoryRepository
- Neo4jChatMemoryRepository
如何使用ChatMemory
入门
此处就以最简单的实现 MessageChatMemoryAdvisor 和 InMemoryChatMemoryRepository为例来实践一下
@Configuration
public class AiConfiguration {
private final ChatMemoryRepository chatMemoryRepository;
@Bean
public ChatMemory chatMemory() {
return MessageWindowChatMemory.builder()
.chatMemoryRepository(chatMemoryRepository)
.maxMessages(10)
.build();
}
@Bean
public ChatClient chatClient(ChatClient.Builder chatClientBuilder){
return chatClientBuilder
.defaultAdvisors(MessageChatMemoryAdvisor.builder(chatMemory()).build())
.build();
}
}
- 提供一个
InMemoryChatMemoryRepository的bean。 表示对话的历史记录都是记录在内存中的,重启后消失 MessageChatMemoryAdvisor 表示对话的历史记录作为列表简单的保存起来,当下一轮交互时就将其查出来然后与本轮提问一起交给LLM。其只是简单的把对话记录按照ChatId存储在了List中。
Prompt{
[
UserMessage{content='你好?'},
AssistantMessage [textContent=你好!有什么可以帮您的吗?😊, UserMessage{content='如何提高英语口语,不要超出50字?', AssistantMessage [ textContent=多听多说,模仿发音,每天练习10分钟,与母语者交流,积累常用表达,不怕犯错。}],
SystemMessage{textContent=' You are a helpful assistant.
进阶
除了 MessageChatMemoryAdvisor,SpringAI还默认提供了两个 BaseChatMemoryAdvisor的继承类。
- PromptChatMemoryAdvisor
public class PromptChatMemoryAdvisor implements BaseChatMemoryAdvisor {
private final ChatMemory chatMemory;
}
从其源码上来看,其还是基于ChatMemory的。那就说明,对话的历史记录保存在什么介质里还是由ChatMemory的选择决定的,例如如果选择 InMemoryChatMemoryRepository,则对话历史还保存在内存中的。但是对话历史记录的使用方式与 MessageChatMemoryAdvisor 就不一样了。
下面是与LLM交互的request日志,从日志中我们可以看到SpringAI先是修改了systemText,给其加了一个prompt模版,要替换的内容为{memory},然后其将对话历史内容插入到了这个prompt模版中。仔细看一下下面的request,包括了一条UserMessage 和AssitantMessage。
将对话的历史记录以
request: AdvisedRequest[chatModel=OpenAiChatModel, userText=王二狗住在哪里?,
systemText=You are a helpful assistant
Use the conversation memory from the MEMORY section to provide accurate answers.
---------------------
MEMORY:
{memory}
---------------------
, systemParams={memory=
USER:让我们来谈谈王二狗:男,爱好女,家住天津,夫妻和睦,育有一子。
ASSISTANT:王二狗的生活听起来很幸福。他和妻子关系和睦,还有一个孩子,说明家庭生活很美满。你想了解王二狗的哪些方面呢?比如他的工作、兴趣爱好,还是其他的事情?}
- VectorStoreChatMemoryAdvisor
public class VectorStoreChatMemoryAdvisor implements BaseChatMemoryAdvisor {
private final VectorStore vectorStore;
}
这个就比较高级了,从其源码可见其使用了一个VectorStore类型而不是ChatMemory了。VectorStore就是存储对话历史记录的地方,例如向量数据库,但是是以Vector的形式。
首先,其将对话历史转化成vector后保存向量数据库中,下图是其在PgVector存储的样子

当开启下一轮互动的时候,SpringAI首先会将用户的问题转化为vector,然后使用语义查询算法去vector数据库中查询相关值,然后取前几个关联度最强的记录(TopK)。而后将其于本轮的问题一起提交给LLM。
下面是request log,可见其将从vector数据库中查出来的信息填到了一个systemMessage的一个prompt中去了。
request: AdvisedRequest[chatModel=OpenAiChatModel [
userText=王二狗有几个子女?, systemText=You are a helpful assistant
Use the long term conversation memory from the LONG_TERM_MEMORY section to provide accurate answers.
---------------------
LONG_TERM_MEMORY:
{long_term_memory}
---------------------
,systemParams={long_term_memory=
王二狗有几个子女?
王二狗有几个子女?
王二狗住在哪里?
王二狗住在天津。
让我们来谈谈王二狗:男,爱好女,家住天津,夫妻和睦,育有一子。
王二狗的生活看起来很幸福。他住在天津,夫妻和睦,育有一子,这样的家庭关系通常会带来很多快乐和支持。你想了解更多关于王二狗的事情吗?比如他的工作、兴趣爱好,还是家庭生活的细节?},
advisors=[], advisorParams={chat_memory_conversation_id=王二狗}...}]
总结
本文主要展示了如何将SpringAI集成到SpringBoot程序中。比较深入的探讨了如何使用ChatMemory来给LLM提供语义辅助,通过本文你已经可以搭建一个初级ChatRobot.
源码
一如既往,你可以从GitHub获取到本文的源码:AI-exploration