
[版权申明] 非商业目的注明出处可自由转载 出自:shusheng007
本文基于SpringAI 1.0.0-RC1版本
概述
通过前面几篇文章我们已经熟悉了如何通过SpringAI来使用LLM了, 掌握前面的知识足以开发一个聊天机器人了,但是LLM本身存在一些局限性。
RAG(Retrieval Augmented Generation)是什么?解决什么问题?
Retrieval Augmented Generation(RAG)是一种将信息检索与生成式大语言模型(LLM)结合的技术,旨在解决传统 LLM 的以下核心问题:
- 知识局限性:LLM 依赖训练数据的静态知识库,无法实时获取最新或特定领域信息,导致生成内容过时或不准确。例如训练数据截止2025-04-01,那么你问他4月2号的事她肯定不知道。
- 幻觉现象:LLM 可能基于统计模式生成看似合理但缺乏事实依据的内容(如虚构数据),俗称一本正经瞎JB扯。
- 上下文不足:无法解决需要外部知识支持的复杂问题,例如你问她:王二狗8岁时偷看隔壁翠花洗澡穿的是什么衣服,LLM就懵逼了。
如何实现RAG
RAG 的核心原理:
- 检索阶段:根据用户查询,从外部知识库(如向量数据库)中检索相关文档或片段。
- 生成阶段:将检索到的上下文与用户输入结合,通过 LLM 生成更准确、信息量更大的响应。
例如,当用户询问“王二狗处过哪些女朋友,分别介绍一下?”时,RAG 会从向量数据库中查询王二狗前女朋友们的信息,然后结合问题一起交给LLM,而非仅依赖模型训练数据,因为模型连王二狗是谁都不知道!
RAG核心原理就两条:向LLM提问时先去找点跟这个问题相关的资料,然后把问题和资料都交给LLM,LLM根据资料来给出具体的回答。过程如此的简单朴素有没有?但别看原理很简单,但是实现起来却有很多困难要解决:
- 资料哪里来,以什么形式存储?
- 如何快速高效的从资料库中查出与问题相关的资料?
- 如何将这些资料和问题合情合理的提交给LLM?(LLM就和一个人一样,你一下给它个国家图书馆它也查不过来!)
为了解决上面的问题,业界逐渐摸索出了很多解决方案:资料(文本,图片和音视频等)一般以向量的形式被存储在向量数据库中,而将这些资料转化为向量时涉及到了Embeding模型,但从这些向量数据库中检索时又涉及到了很多检索算法,资料检索出来后又涉及到了prompt将其提交给LLM处理... 你看着陌生的词不断地往外蹦,心是不是都要碎了? 不过不用担心,如果你只是探索到应用层,也就是如何使用他们,那么只要了解一下他们就可以了,还是比较简单的。
这不SpringAI已经等不及上场了。如下图所示,其分为了Offline与Online两部分
- offline
解决如何将资料存入向量数据库中的问题。这个过程包括ETL三个步骤,这个过程一般是离线处理的。
- online
解决在与LLM交互的时候,如何实时从向量数据库获取与问题相关的数据并提交给LLM的问题。
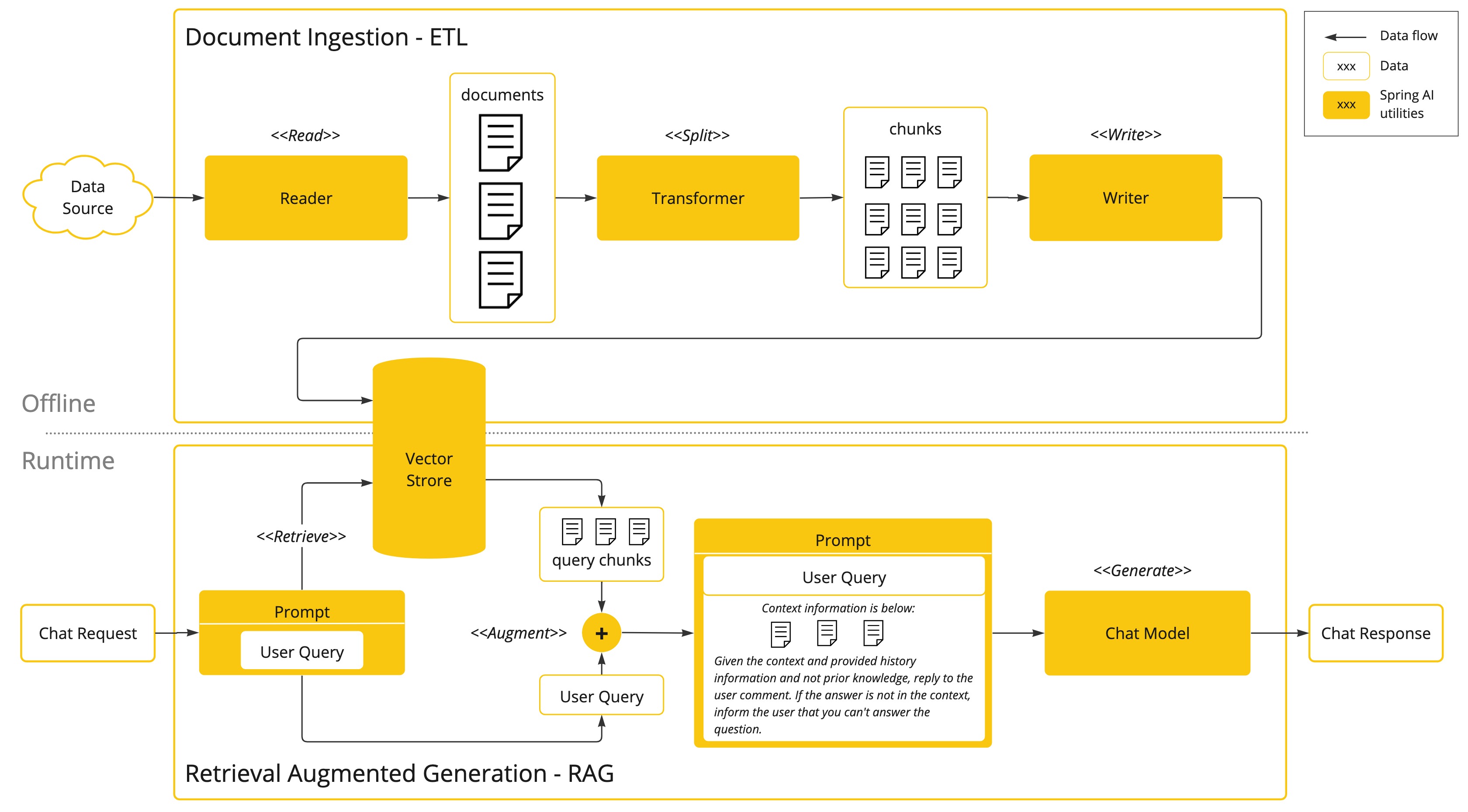
Spring AI 的 ETL Pipeline
Spring AI 提供了一套完整的 ETL(Extract-Transform-Load)流水线,用于将原始数据转换为向量存储,其核心流程如下:
1 Extract(提取)
从各种来源获取文档,例如从PDF,Markdown,Json等文档。其职责由 DocumentReader接口来承担
public interface DocumentReader extends Supplier<List<Document>> {
default List<Document> read() {
return get();
}
}
其有很多实现,例如 MarkdownDocumentReader,PagePdfDocumentReader等
// 示例:读取 PDF 文件
DocumentReader pdfReader = new PagePdfDocumentReader("path/to/file.pdf");
List<Document> documents = pdfReader.get();
2 Transform(转换)
将Extract中提取的文档进行转换,转化的方式有很多,例如将文档按Token拆分,保留语义完整性。其职责由 DocumentTransformer接口承担。
public interface DocumentTransformer extends Function<List<Document>, List<Document>> {
default List<Document> transform(List<Document> transform) {
return apply(transform);
}
}
例如下面展示了一个使用AI大模型来从文档中提取关键字的一个transformer,下面展示的是每个文档提取5个关键字
List<Document> enrichDocuments(List<Document> documents) {
KeywordMetadataEnricher enricher = new KeywordMetadataEnricher(this.chatModel, 5);
return enricher.apply(documents);
}
3 Load(加载)
将Transform转换好的文档,根据 EmbeddingModel转化为向量,然后存储在向量数据库中。其职责由 DocumentWriter接口承担
public interface DocumentWriter extends Consumer<List<Document>> {
default void write(List<Document> documents) {
accept(documents);
}
}
private final VectorStore vectorStore;
vectorStore.write(transformDocuments);
SpringAI为上面三个接口都提供了很多常用的实现类,足够大多数场景使用了,但如果不够用就需要我们自己去自定义了。
Spring AI 实现 RAG
SpringAI使用Advisor机制来实现RAG, 其提供了 QuestionAnswerAdvisor 和 RetrievalAugmentationAdvisor两个Advisor。 QuestionAnswerAdvisor比较早,RetrievalAugmentationAdvisor是设计用来替换 QuestionAnswerAdvisor的,所以我们主要来了解一下 RetrievalAugmentationAdvisor的使用方法吧。
RetrievalAugmentationAdvisor
RetrievalAugmentationAdvisor 实现了前面所述RAG的online部分,即
- 将问题转化为向量
- 使用此向量从vector数据库中检索相关信息
- 将检索到的内容与问题构成prompt后调用LLMs
其遵循了 Modular RAG 架构,内置了常用的 RAG 模块
下面的模块都是作用在上面的3个过程中,目的就是使LLM可以更好的理解问题并回答问题。下面的模块是按顺序执行的,有则执行没有则跳过。
模块化组件
-
QueryTransformer:对用户原始问题进行预处理或格式化(如文本清洗、模板填充),原始Query可以连续经过多个
QueryTransformer去转换 。public interface QueryTransformer extends Function<Query, Query> { Query transform(Query query); }可见,其将一个
Query转化为另一个Query -
QueryExpander:基于上下文或外部知识扩展查询词(如同义词扩展、实体识别),其会将原始
Query扩展为一个或者多了Query。public interface QueryExpander extends Function<Query, List<Query>> { List<Query> expand(Query query); }可见,其将一个
Query扩展为List<Query>了 -
DocumentRetriever:执行向量检索,从 Vector Store中查询相关文档,每一个
Query会拉取一个List<Document>。public interface DocumentRetriever extends Function<Query, List<Document>> { List<Document> retrieve(Query query); }可见,其通过一个
Query获取了一个List<Document> -
DocumentJoiner:将多条检索结果拼接成模型可消费的上下文块。
public interface DocumentJoiner extends Function<Map<Query, List<List<Document>>>, List<Document>>{ List<Document> join(Map<Query, List<List<Document>>> documentsForQuery); }可见,其将
Map<Query, List<List<Document>>>转化为List<Document>。那个Map是由前面的模块产生的,前面的QueryExpander将一个Query扩展为多个,然后DocumentRetriever会为每一个Query拉取一个List<Document>,这样就形成了以Query为key,List<Document>为value的Map。 -
QueryAugmenter:在生成最终提示时,将检索到的上下文与原始查询融合(例如:在 prompt 前添加 “Context:” 部分) Medium。
public interface QueryAugmenter extends BiFunction<Query, List<Document>, Query> { Query augment(Query query, List<Document> documents); }可见,其使用
List<Document>增强了原始Query。
实践
前面介绍了那个多理论,让我们动手实践一下。编程时一门理论与实践想结合的技术,个人认为实践要大于理论。那些绝顶聪明的人应该让他们去搞前言科学理论研究,编程的有我们这些比较笨的人来就行...
准备知识库(offline)
j假设我们有如下内容的一个名为 dog2wang_profile.txt文件,我们要如何将其通过ETL来存储到Vector store里呢?
我叫王二狗,于公元前3000年01月01日出生于X星球,
我天生神力,聪明绝顶,3岁即可吟诗3000首,5岁单手举重10万斤,
13岁带领10万王家军队探索太空,15岁征服太阳系,18岁统治银河系...
我们将其放在resource文件下,通过下面的过程就可以将其存放到Vector Store。
- 安装向量数据库
此处我们使用PostgreSQL数据库,配合其扩展PgVector。在此不得不说自从用了PostgreSQL就感觉MySql是一坨屎,真后悔没有早点尝试PostgreSQL...
此处我们使用docker-compose来安装,docker compose文件内容如下:
services:
postgres:
image: pgvector/pgvector:pg17
environment:
POSTGRES_DB: vectordb
POSTGRES_USER: vector-admin
POSTGRES_PASSWORD: vector-admin
ports:
- "5434:5432"
volumes:
- postgres_data:/var/lib/postgresql/data
volumes:
postgres_data:
- 配置向量数据库连接
首先在application.yml中配置PostgreSQL的连接信息,相信这块springbooter已经滚瓜烂熟了。然后就是配置vectorstore。
spring:
datasource:
url: jdbc:postgresql://localhost:5434/vectordb
username: vector-admin
password: vector-admin
ai:
vectorstore:
pgvector:
initialize-schema: true
index-type: HNSW
distance-type: COSINE_DISTANCE
dimensions: 1536
initialize-schema: 是否让springAI帮你初始化向量数据库,例如建表什么的
index-type: 设置向量的索引类型
distance-type: 设置向量搜索时候的算法
dimensions: 设置向量维度,这个维度与你使用的embedding model有关,例如open API 的是1536维。
上面的配置会生成如下的sql脚本
create table vector_store
(
id uuid default uuid_generate_v4() not null primary key,
content text,
metadata json,
embedding vector(1536)
);
alter table vector_store
owner to "vector-admin";
create index spring_ai_vector_index
on vector_store using hnsw (embedding vector_cosine_ops);
- 存放数据
这个过程我们会使用SpringAI提供的ETL来完成,我们会将 dog2wang_profile.txt文件保存到向量数据库中
public class IngestionService {
private final VectorStore vectorStore;
@Value("classpath:/static/dog2wang_profile.txt")
private Resource personInfo;
public void ingestData() {
//Extract
DocumentReader txtReader = new TextReader(personInfo);
List<Document> documents = txtReader.read();
//Transformer
DocumentTransformer textSplitter = new TokenTextSplitter();
List<Document> transformDocuments = textSplitter.transform(documents);
//Load
vectorStore.write(transformDocuments);
log.info("Vector store loaded with data");
}
}
代码中的注释已经说明了ETL的三个过程,最终其在数据库中的结果如下
[
{
"id": "6d1f53d6-e40e-4775-abb2-c7939cd0d42f",
"content": "我叫王二狗,于公元前3000年01月01日出生于X星球,\r\n我天生神力,聪明绝顶,...",
"metadata": {"source": "dog2wang_profile.txt", "charset": "UTF-8"},
"embedding": "[-0.0009999517,-0.02966744,-0.028316513,-0.024343194,-0.035071153,0.013787413,...]"
}
]
RAG
我们已经构建了知识库,是时候使用其作为context来增强我们的智能助手了
最重要的就是RetrievalAugmentationAdvisor,我们已经在前面已经介绍了其使用方式,前面已经说过了为了构建出更好的prompt,可以使用各种技术:
QueryTransformer,QueryExpander,DocumentRetriever,DocumentJoiner,QueryAugmenter。
此处为了简单我们只使用其最重要的一步DocumentRetriever。
public MyChatResponse chat(MyChatRequest myChatRequest) {
RetrievalAugmentationAdvisor retrievalAugmentationAdvisor = RetrievalAugmentationAdvisor.builder()
.documentRetriever(VectorStoreDocumentRetriever.builder()
.similarityThreshold(0.60)
.topK(3)
.vectorStore(vectorStore)
.build())
.build();
String chatId = Optional
.ofNullable(myChatRequest.getChatId())
.orElse(UUID.randomUUID().toString());
Message userMsg = new UserMessage(myChatRequest.getQuestion());
String systemMessage = """
You are a helpful assistant.
Use your training data to provide answers about the questions.
If the requested information is not available in your training data or user provided context, use the provided Tools to get the information.
If the requested information is not available from any sources, then respond by explaining the reason that the information is not available.
""";
SystemPromptTemplate systemPromptTemplate = new SystemPromptTemplate(systemMessage);
String response = chatClient
.prompt(systemPromptTemplate.create())
.user(myChatRequest.getQuestion())
.advisors(advisorSpec ->
advisorSpec.
param(ChatMemory.CONVERSATION_ID, chatId))
.advisors(retrievalAugmentationAdvisor)
.call()
.content();
return new MyChatResponse(chatId, response);
}
此处我们只需要重点关注如何构建的 RetrievalAugmentationAdvisor以及如何将其集成到 ChatClient中即可。
交互结果:
问:
http POST localhost:8080/ai/chat chatId=王二狗 question=介绍一下王二狗
答:
{
"answer": "王二狗于公元前3000年01月01日出生于X星球,天生神力,聪明绝顶。3岁时能够吟诗3000首,5岁时单手举重10万斤。13岁时,他带领10万王家军队探索太空,15岁征服了太阳系,18岁则统治了银河系。"
"chatId": "王二狗"
}
LLM竟然认识了王二狗,可见其利用了我们的知识库。我们再问一下LLM关于王二狗媳妇的信息,这个信息不在我们的知识库内,看其如何回答。
问:
http POST localhost:8080/ai/chat chatId=王二狗 question=介绍一下王二狗媳妇
答:
{
"answer": "我不知道。",
"chatId": "王二狗"
}
总结
RAG意义非常重大,毕竟这个世界上有太多数据是私有的了,特别是在这个数据被看做黄金的年代,各个企业对自身数据的重视程度不断地提高。所以通过RAG这种技术,企业就可以将自己的数据喂给私有部署的大模型上...
所以说这块是AI应用中非常重要的一个方面,一定要掌握
源码
一如既往,你可以从GitHub获取到本文的源码:AI-exploration